Здравствуйте, уважаемые читатели блога7j.ru. Уж не знаю, почему,
но моя муза, наверное, улетела отдыхать на моря. Авторское
вдохновение потихоньку иссякло, и я не могу нарыть тем для новых
материалов. Поэтому пришло время потрусить поисковики. Но
парсинг выдачи Гугл – дело заковыристое.
Приходится с прокси мучиться или десятки капч решать… На что
товарищи по цеху говорят, что я отстал от времени и предлагают
догнать прогресс с помощью XMLRiver.
Когда поисковики вставляют палки в колеса
Google и другие поисковые системы всячески борются за повышение
релевантности выдачи. Но тогда почему сбор семантического ядра, его
оптимизация или снятие позиций сайта превращается для вебмастера в
танец с бубном. Причем такие пляски продолжаются уже не первый год.
И я, видимо, уже привык осуществлять парсинг
Google под свой танец – обходя блокировки поисковиков с
помощью прокси и антикапч.
Но, видимо, практикуемый вашим покорным слугой способ давно
устарел. О чем не раз уже намекали мои сотоварищи. И вот
представился случай постичь более прогрессивный метод парсинга – с
помощью XMLRiver.
Краткая характеристика сервиса
Парсер поисковой выдачи Гугла и Яндекса
позволяет осуществлять выборку данных из SERP в формате XML. Его
механизм схож с принципом работы Яндекс.XML. Но в отличие от него
XMLRiver предоставляет прямую выдачу и как следствие, расширенный
набор настроек, позволяющих сегментировать получаемые данные по
множеству параметров.
Сервис можно использовать для:
Проверки наличия веб-страниц сайта в поисковом индексе.
Снятия позиций.
Глубокого анализа поисковой выдачи по заданным запросам.
Сбора семантического ядра.
Сбора данных для кластеризации СЯ.
Его преимущества по сравнению с конкурентными решениями:
Возможность парсинга не только органических результатов поиска,
но и отдельных блоков выдачи (колдунщики, быстрые ответы и т.д.), а
также Google News, Google Images и Google Shopping.
Анализ рекламных объявлений конкурентов.
Скорость сбора данных по Google превышает 15 тысяч запросов в
час.
Сбор данных с сервиса можно осуществлять с помощью бесплатной
программы XMLRiver.Parser с последующей
выгрузкой данных в CSV формате.
Нативный API сервиса без проблем интегрируется с популярным
специализированным ПО и веб-приложениями, осуществляющими парсинг
выдачи основных поисковых систем.
*при клике по картинке она откроется в полный размер в новом
окне
Схема работы с XMLRiver:
Регистрируемся.
Пополняем счет.
Настраиваем параметры гео и необходимые опции.
Копируем URL для запросов.
Вставляем в используемую программу ключ API и осуществляем
беспроблемный (без капч и блокировок) сбор данных из результатов
поиска.
Услуги сервиса предоставляются в виде подписок с оплатой за
каждый запрос. Стоимость одного кило запросов к Google стартует от
10 руб., к Яндексу – от 8 руб.
А теперь проверим, насколько рассматриваемый сервис удобен и
полезен для решения насущных проблем вебмастера…
Немного эгоизма – решаю свою проблему
Быстрый и беспроблемный парсинг
Гугла мне нужен, чтобы найти тематические форумы для
проставления ссылок, нынче это называется крауд-маркетинг. Для
этого в связке с XMLRiver будет трудиться программа
XMLRiver.Parser.
Что да как делаем (пошагово):
Регистрируемся на сайте.
В личном кабинете пользователя сервиса переходим в раздел
«Финансы» и пополняем счет любым удобным для нас способом. Даже
можно и криптовалютой.
*при клике по картинке она откроется в полный размер в новом
окне
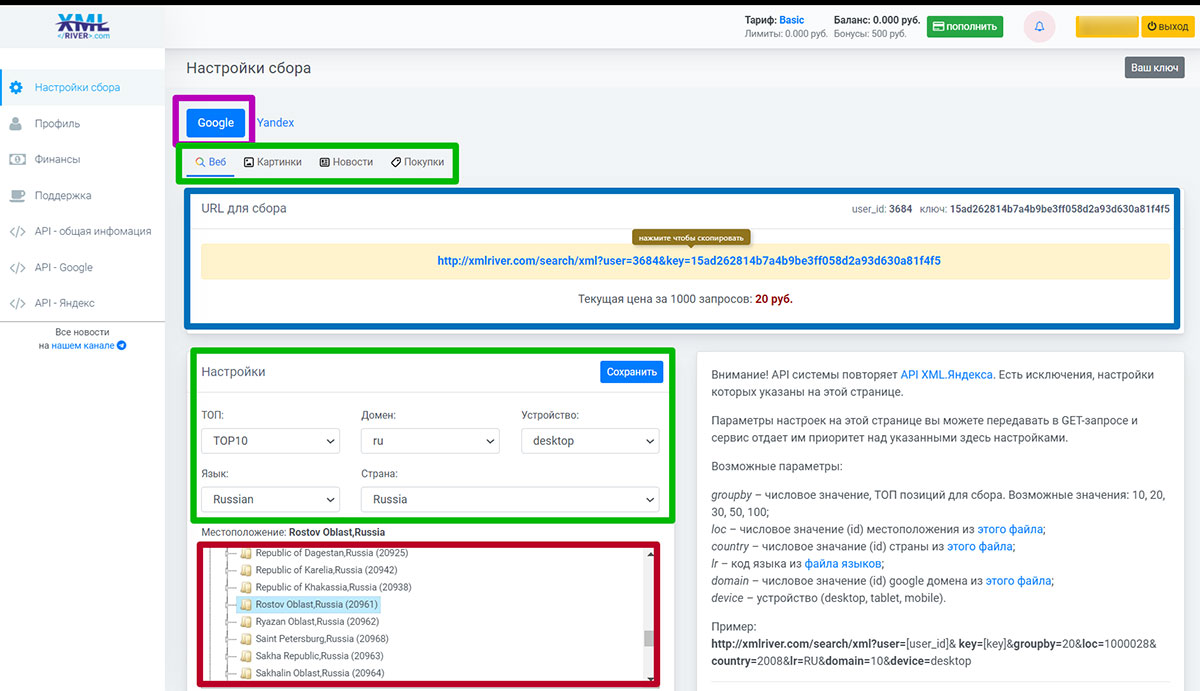
На вкладке «Настройки сбора» выбираем поисковик, тип выдачи
(органика, поиск по картинкам, новости или покупки). В нашем случае
это будет Google органика.
*при клике по картинке она откроется в полный размер в новом
окне
Перед тем как парсить выдачу Google, в
настройках устанавливаем охват выборки по ТОПу, доменной зоне, типу
устройства, языку и гео. Ставим топ20, т.к. форумы, которые
находятся дальше, ранжируются плохо и нам не нужны.
В дополнительных параметрах указываем расширенные форматы
выдачи и блоки SERP, которые нужно анализировать. А также (если
нужно) активируем подсветку ключевых слов в выборке и задаем
календарный период. Для нашей задачи всё это не надо.
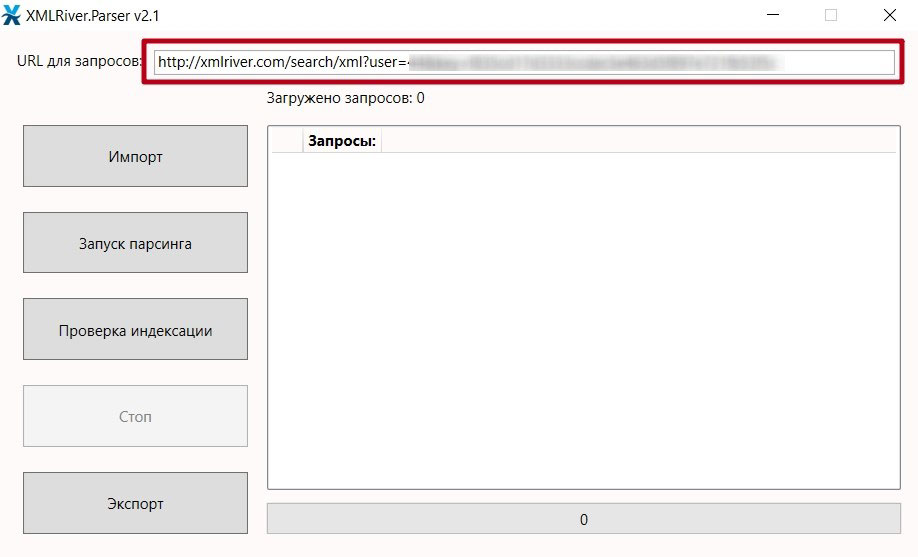
Теперь осталось скопировать значение URL-адреса для сбора (см.
скриншот выше) и вставить его в программу.
*при клике по картинке она откроется в полный размер в новом
окне
Останавливаемся, чтобы проанализировать содеянное.
Мы настроили параметры XMLRiver, которые позволят парсить
выдачу Гугла в нужном направлении. И затем легко и быстро
подключили сервис к сторонней программе.
Что дальше:
Нам нужны ключевые слова, по которым ранжируется наша страница,
к каждому из которых мы добавим следующие конструкции:
inurl:showthread
inurl:viewtopic
inurl:forum
inurl:showtopic
Сделать это проще всего в notepad++. Копируем список фраз в 4
разных документа (у нас 4 конструкции, которые надо добавить к
фразам) и делаем замену, используя регулярное выражение (обратите
внимание на режим поиска внизу окна):
В результате данной замены получаем такой список:
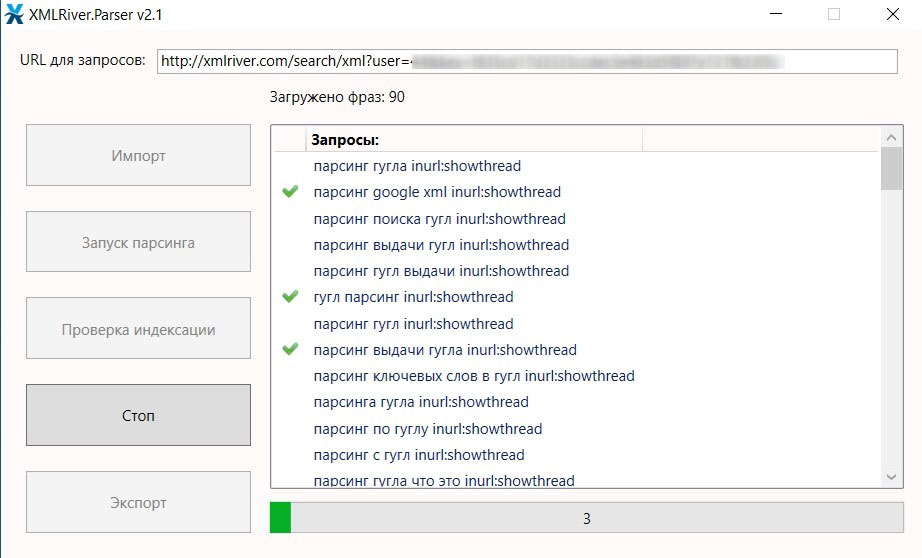
Проделываем тоже самое для трёх других конструкций и объединяем
3 списка. А дальше самое интересное – импортируем окончательный
список фраз в XMLRiver.Parser и запускаем сбор данных:
*при клике по картинке она откроется в полный размер в новом
окне
Дальше экспортируем полученные результаты и получаем самый сок,
лучшие по мнению Google топики на форумах, где обсуждают искомую
тему:
*при клике по картинке она откроется в полный размер в новом
окне
Впечатления от работы приложения, интегрированного с
XMLRiver:
Буквально за каких-то пять минут программа уже собрала из
поисковой выдачи тысячи топов за очень скромный бюджет.
Насколько хорош сервис?
По сравнению с более старыми способами XMLRiver позволяет
намного быстрее парсить SERP в Гугл. Например,
процесс сбора семантики занимает не несколько часов, а в среднем
20-30 мин. И при этом не нужно заморачиваться с заполнением
проверочных капч от поисковиков или с подключением «антикапчевых»
сервисов.
Конечно, для повышения эффективности анализа выдачи можно
использовать прокси. Но с данным инструментом тоже не все так
гладко. Ведь найти поставщика качественных proxy очень сложно. К
тому же даже самые надежные айпишники обладают одним негативным
свойством – не вовремя вылетать, сбоить и в разы замедлять скорость
интернет-соединения. В результате процесс парсинга превращается в
процедуру длиною в жизнь.
Да и стоимость использования антикапч и прокси тоже влетает
вебмастеру в копеечку, что сопоставимо с оплатой услуг
XMLRiver.
Тогда как парсить Google быстро, выгодно и без
головной боли? Конечно же, с помощью XMLRiver. При тестировании
возможностей сервиса я выделил следующие его преимущества:
Простота интеграции – с ней справится даже новичок. Для
интеграции инструмента со сторонней программой достаточно лишь
вставить один URL для запросов.
Большое количество настроек на борту – они позволяют указать
гео и блоки выдачи, которые нужно парсить (при условии, что
программа отображает дополнительные блоки выдачи).
Обеспечивает бесперебойный режим работы.
Охватывает все типы выдач Google – поиск по картинкам, товары,
новости и обычный SERP.
Низкая стоимость.
Горько это признавать, но я действительно отстал в своем
профессиональном развитии. Прокси и антикапчи – уже прошлый век.
Сегодня все продвинутые SEO-специалисты и вебмастера парсят выдачу
с помощью XMLRiver. Ведь это удобней, эффективней и выгоднее.
Удачи вам! До скорых встреч на страницах блога7j.ru